{kind=link}
Here's something you might be interested in.
Ask a Hipster — Advice you didn't know you needed
Big Screen — Movie commentary
Blurt — Music's inside track
Booze News — San Diego spirits
Classical Music — Immortal beauty
Classifieds — Free and easy
Close to Home — What it’s like on the street where you live
Cover Stories — Front-page features
Drinks All Around — Bartenders' drink recipes
Excerpts — Literary and spiritual excerpts
Feast! — Food & drink reviews
Feature Stories — Local news & stories
Fishing Report — What’s getting hooked from ship and shore
From the Archives — Spotlight on the past
Golden Dreams — Talk of the town
The Gonzo Report — Making the musical scene, or at least reporting from it
Letters — Our inbox
Movies@Home — Local movie buffs share favorites
Movie Reviews — Our critics' picks and pans
Musician Interviews — Up close with local artists
Neighborhood News from Stringers — Hyperlocal news
News Ticker — News & politics
Obermeyer — San Diego politics illustrated
Outdoors — Weekly changes in flora and fauna
Overheard in San Diego — Eavesdropping illustrated
Poetry — The old and the new
Reader Travel — Travel section built by travelers
Reading — The hunt for intellectuals
Roam-O-Rama — SoCal's best hiking/biking trails
San Diego Beer — Inside San Diego suds
SD on the QT — Almost factual news
Sheep and Goats — Places of worship
Special Issues — The best of
Street Style — San Diego streets have style
Surf Diego — Real stories from those braving the waves
Theater — On stage in San Diego this week
Tin Fork — Silver spoon alternative
Under the Radar — Matt Potter's undercover work
Unforgettable — Long-ago San Diego
Unreal Estate — San Diego's priciest pads
Your Week — Daily event picks
Bradley Voytek’s voyage: from Deep Space Nine to deep data mine
Bill Gates: “I’m always amazed by the disconnect between what we see in the news and the reality of the world around us.”
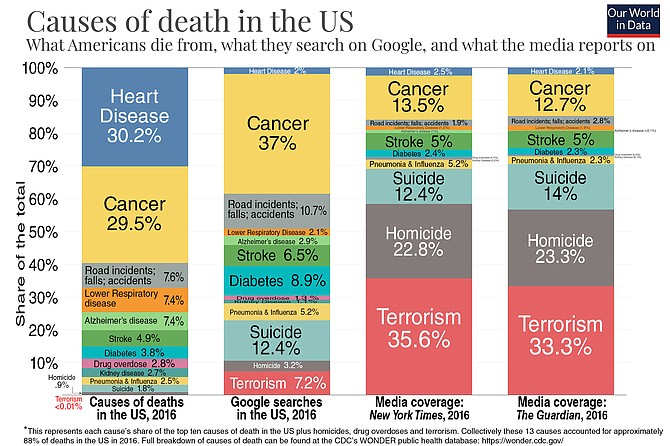
Modified rendering of OurWorldinData.org chart based on the data science project done by Voytek’s students.
In 2010, Bradley Voytek was a frustrated grad student working toward a Ph.D. in neuroscience at UC Berkeley. He was frustrated because there was too much data. “I had to learn the basics of the brain, and there are three million peer-reviewed papers in neuroscience alone in the database run by the National Institutes of Health.” He needed a tool that could provide some kind of shortcut, something like the program he’d written as an undergrad working in a neuroscience research lab that allowed him to do two weeks’ worth of copy-and-pasting in a single day. (To his superiors, he recalls, “it was like I had done a magic trick.”) Over reruns of Star Trek: Deep Space Nine, he told his wife — a software developer — about an idea for text mining all those papers via something like Facebook’s friend-suggesting algorithm, using it “to find missing links between ideas.” “I could totally code that faster than you,” she replied, and she was right.
Among their tool’s discoveries: “there were a huge number of papers that talked about migraines and serotonin, and a huge number that talked about serotonin and the brain region called the striatum, but only 16 papers that talked about the striatum and migraines.” He doesn’t take credit for starting an investigation, but he does note that “since we published our paper on that, there have been quite a number of papers looking at that link.”

Dr. Bradley Voytek: neuroscientist by day, data scientist by other days.
Similarly, he doesn’t take credit for the creation of the new Data Science major at UCSD, where he’s an associate professor. But he does grant that the explosive growth of the undergraduate Intro to Data Science class he invented — from 24 students initially to over 500 in its third iteration — helped move things along. The students “had a massive hunger to learn more about discovering the world through this digital exhaust of information that we’re constantly leaving behind us. There’s way more data than there’s ever been, which allows you to do way more things.” For instance, “one aspect of data science involves learning by quantifying observations, sometimes by incorporating wildly different kinds of data.”
He gives the example of a Facebook employee trying to figure out the likelihood that a user will click on a given ad. “You might have access to the stuff in the status updates — that’s text. Also, that user has friends — that’s a network.” The update is uploaded from a particular place and time. And sometimes, there’s a picture. “Every image you upload to Facebook is run through a computer vision algorithm that tries to figure out what it is.” He right clicks on one of his own uploads and selects “Inspect.” The result: “Image may contain: two people, including Bradley Voytek, people sitting, table, tree, outdoor, nature.” (In another photo, Facebook noticed he’d grown a beard.) The Facebook worker has to find a way to turn all that data into a single number indicating probability of ad click, “because that’s how they make money.”
This is how technology seems to hit. “You have companies that do things. You have early adopters. Then you have consequences and backlash. Then the government comes in and makes laws, and the academics come in and figure things out.” He cites the car as a famous example, noting that driving is “still the most dangerous thing we do on a daily basis,” but at least it’s been regularized. “I think you have something similar now with social media. People are pissed at Twitter and social media,” in part because while mobthink and echo chambers may be good for Twitter, they are not as good for its users. “If I can teach students the cautionary tales about what kind of data we’re leaving behind and what kind of data people are collecting and what kind of biases that creates, then hopefully when they go to work for those tech companies, they’ll take some of that with them.”
On June 11, Bill Gates tweeted, “I’m always amazed by the disconnect between what we see in the news and the reality of the world around us. As my late friend Hans Rosling would say, we must fight the fear instinct that distorts our perspective.” He illustrated his point with a chart comparing “what Americans die from, what they search on Google, and what the media reports on.” According to the chart, heart disease and cancer kill 60 percent of us, but account for only 40 percent of Google searches and 16 percent of deaths reported in the New York Times. Terrorism, by comparison, kills .01 percent, but gets 7.2 percent on Google and 35 percent in the Times. The chart’s source: a group final project from Voytek’s Data Science in Project class.
Here's something you might be interested in.
Bradley Voytek’s voyage: from Deep Space Nine to deep data mine
Bill Gates: “I’m always amazed by the disconnect between what we see in the news and the reality of the world around us.”
Bradley Voytek’s voyage: from Deep Space Nine to deep data mine
Bill Gates: “I’m always amazed by the disconnect between what we see in the news and the reality of the world around us.”
Modified rendering of OurWorldinData.org chart based on the data science project done by Voytek’s students.
In 2010, Bradley Voytek was a frustrated grad student working toward a Ph.D. in neuroscience at UC Berkeley. He was frustrated because there was too much data. “I had to learn the basics of the brain, and there are three million peer-reviewed papers in neuroscience alone in the database run by the National Institutes of Health.” He needed a tool that could provide some kind of shortcut, something like the program he’d written as an undergrad working in a neuroscience research lab that allowed him to do two weeks’ worth of copy-and-pasting in a single day. (To his superiors, he recalls, “it was like I had done a magic trick.”) Over reruns of Star Trek: Deep Space Nine, he told his wife — a software developer — about an idea for text mining all those papers via something like Facebook’s friend-suggesting algorithm, using it “to find missing links between ideas.” “I could totally code that faster than you,” she replied, and she was right.
Among their tool’s discoveries: “there were a huge number of papers that talked about migraines and serotonin, and a huge number that talked about serotonin and the brain region called the striatum, but only 16 papers that talked about the striatum and migraines.” He doesn’t take credit for starting an investigation, but he does note that “since we published our paper on that, there have been quite a number of papers looking at that link.”
Dr. Bradley Voytek: neuroscientist by day, data scientist by other days.
Similarly, he doesn’t take credit for the creation of the new Data Science major at UCSD, where he’s an associate professor. But he does grant that the explosive growth of the undergraduate Intro to Data Science class he invented — from 24 students initially to over 500 in its third iteration — helped move things along. The students “had a massive hunger to learn more about discovering the world through this digital exhaust of information that we’re constantly leaving behind us. There’s way more data than there’s ever been, which allows you to do way more things.” For instance, “one aspect of data science involves learning by quantifying observations, sometimes by incorporating wildly different kinds of data.”
He gives the example of a Facebook employee trying to figure out the likelihood that a user will click on a given ad. “You might have access to the stuff in the status updates — that’s text. Also, that user has friends — that’s a network.” The update is uploaded from a particular place and time. And sometimes, there’s a picture. “Every image you upload to Facebook is run through a computer vision algorithm that tries to figure out what it is.” He right clicks on one of his own uploads and selects “Inspect.” The result: “Image may contain: two people, including Bradley Voytek, people sitting, table, tree, outdoor, nature.” (In another photo, Facebook noticed he’d grown a beard.) The Facebook worker has to find a way to turn all that data into a single number indicating probability of ad click, “because that’s how they make money.”
This is how technology seems to hit. “You have companies that do things. You have early adopters. Then you have consequences and backlash. Then the government comes in and makes laws, and the academics come in and figure things out.” He cites the car as a famous example, noting that driving is “still the most dangerous thing we do on a daily basis,” but at least it’s been regularized. “I think you have something similar now with social media. People are pissed at Twitter and social media,” in part because while mobthink and echo chambers may be good for Twitter, they are not as good for its users. “If I can teach students the cautionary tales about what kind of data we’re leaving behind and what kind of data people are collecting and what kind of biases that creates, then hopefully when they go to work for those tech companies, they’ll take some of that with them.”
On June 11, Bill Gates tweeted, “I’m always amazed by the disconnect between what we see in the news and the reality of the world around us. As my late friend Hans Rosling would say, we must fight the fear instinct that distorts our perspective.” He illustrated his point with a chart comparing “what Americans die from, what they search on Google, and what the media reports on.” According to the chart, heart disease and cancer kill 60 percent of us, but account for only 40 percent of Google searches and 16 percent of deaths reported in the New York Times. Terrorism, by comparison, kills .01 percent, but gets 7.2 percent on Google and 35 percent in the Times. The chart’s source: a group final project from Voytek’s Data Science in Project class.
Commentsfeizi
This comment was removed by the site staff for violation of the usage agreement.
June 19, 2019