{kind=link}
Sponsored
Sponsored
In 2010, Bradley Voytek was a frustrated grad student working toward a Ph.D. in neuroscience at UC Berkeley. He was frustrated because there was too much data. “I had to learn the basics of the brain, and there are three million peer-reviewed papers in neuroscience alone in the database run by the National Institutes of Health.” He needed a tool that could provide some kind of shortcut, something like the program he’d written as an undergrad working in a neuroscience research lab that allowed him to do two weeks’ worth of copy-and-pasting in a single day. (To his superiors, he recalls, “it was like I had done a magic trick.”) Over reruns of Star Trek: Deep Space Nine, he told his wife — a software developer — about an idea for text mining all those papers via something like Facebook’s friend-suggesting algorithm, using it “to find missing links between ideas.” “I could totally code that faster than you,” she replied, and she was right.
Among their tool’s discoveries: “there were a huge number of papers that talked about migraines and serotonin, and a huge number that talked about serotonin and the brain region called the striatum, but only 16 papers that talked about the striatum and migraines.” He doesn’t take credit for starting an investigation, but he does note that “since we published our paper on that, there have been quite a number of papers looking at that link.”
Similarly, he doesn’t take credit for the creation of the new Data Science major at UCSD, where he’s an associate professor. But he does grant that the explosive growth of the undergraduate Intro to Data Science class he invented — from 24 students initially to over 500 in its third iteration — helped move things along. The students “had a massive hunger to learn more about discovering the world through this digital exhaust of information that we’re constantly leaving behind us. There’s way more data than there’s ever been, which allows you to do way more things.” For instance, “one aspect of data science involves learning by quantifying observations, sometimes by incorporating wildly different kinds of data.”
He gives the example of a Facebook employee trying to figure out the likelihood that a user will click on a given ad. “You might have access to the stuff in the status updates — that’s text. Also, that user has friends — that’s a network.” The update is uploaded from a particular place and time. And sometimes, there’s a picture. “Every image you upload to Facebook is run through a computer vision algorithm that tries to figure out what it is.” He right clicks on one of his own uploads and selects “Inspect.” The result: “Image may contain: two people, including Bradley Voytek, people sitting, table, tree, outdoor, nature.” (In another photo, Facebook noticed he’d grown a beard.) The Facebook worker has to find a way to turn all that data into a single number indicating probability of ad click, “because that’s how they make money.”
This is how technology seems to hit. “You have companies that do things. You have early adopters. Then you have consequences and backlash. Then the government comes in and makes laws, and the academics come in and figure things out.” He cites the car as a famous example, noting that driving is “still the most dangerous thing we do on a daily basis,” but at least it’s been regularized. “I think you have something similar now with social media. People are pissed at Twitter and social media,” in part because while mobthink and echo chambers may be good for Twitter, they are not as good for its users. “If I can teach students the cautionary tales about what kind of data we’re leaving behind and what kind of data people are collecting and what kind of biases that creates, then hopefully when they go to work for those tech companies, they’ll take some of that with them.”
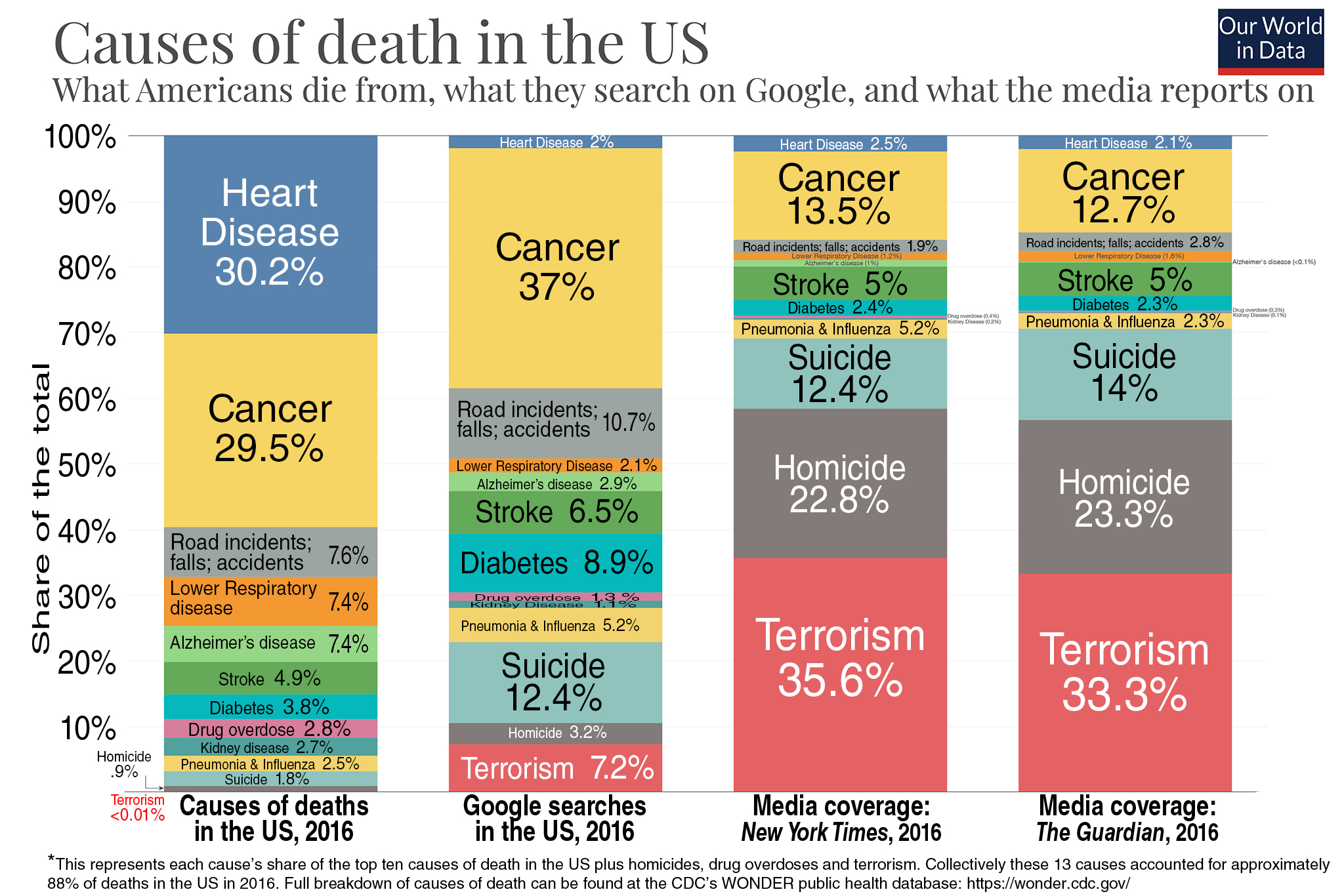
On June 11, Bill Gates tweeted, “I’m always amazed by the disconnect between what we see in the news and the reality of the world around us. As my late friend Hans Rosling would say, we must fight the fear instinct that distorts our perspective.” He illustrated his point with a chart comparing “what Americans die from, what they search on Google, and what the media reports on.” According to the chart, heart disease and cancer kill 60 percent of us, but account for only 40 percent of Google searches and 16 percent of deaths reported in the New York Times. Terrorism, by comparison, kills .01 percent, but gets 7.2 percent on Google and 35 percent in the Times. The chart’s source: a group final project from Voytek’s Data Science in Project class.